

本文最后更新于 2024年12月17日 by 阿喵
#Diffusion #AI Art #Stable Diffusion Web UI
体验在线 AI 画图服务
Midjourney 是一个由同名研究实验室开发的人工智能程序,可根据文本生成图像,于2022年7月12日进入公开测试阶段,用户可透过 Discord 的机器人指令进行操作。该研究实验室由 Leap Motion *的创办人大卫·霍尔兹负责领导。*—— Wikipedia

可以加入 Beta 计划从 Discord 群中向机器人提交作图指令。官网服务也提供付费订阅。
微软借助 OpenAI 的 DALL-E 图像生成 AI ,提供了这个在线图片生成服务。用户输入一段文本提示,仅需数秒即可获得一组 AI 生成的与之匹配的图像。
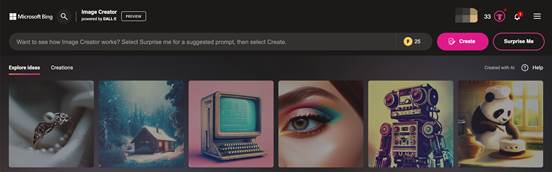
Preview 阶段,每位普通用户媒体可以快速生成 25 次,超过次数需要排队等待。
搭建自己的 AI 作图环境
在线服务效果好,但是有使用次数限制。如果你需要更多的自由度,那么可以考虑自己搭建一套 AI 做图环境。
准备
Stable Diffusion GUI
AI 绘图已经火出圈,自然开源社区里也有许多 Stable Diffusion 的图形界面,方便用户上手体验。
有专门提供给 MacOS 桌面端的 DiffusionBee,还有跨平台的 Stable Diffusion UI v2 。
而本文我们着重介绍可以部署在云端的 Web UI 。
AUTOMATIC1111(简称 A1111)Stable Diffusion Web UI 是为高级用户提供的 Stable Diffusion GUI。
多亏了活跃的开源社区,大多数新功能都会先支持上这个免费的 Stable Diffusion GUI 。
但要使用它并不容易。文档不够详尽,以及提供的茫茫功能列表都会让新手迷茫。
购买一台云主机
登录云主机后,可以先检查一下显卡型号:
Shell $ lspci | grep -i nvidia 00:06.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1)
货真价实,没有问题,那么开始搭建吧!
安装一些必要的依赖软件
Bash # 更新软件包索引 sudo apt-get -y update # 必要软件 sudo apt-get -y install wget git python3 python3-venv python3-pip sudo apt-get -y install aria2 screen # 安装 cuda 软件包,让显卡发挥超能力 wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.0-1_all.deb sudo dpkg -i cuda-keyring_1.0-1_all.deb sudo apt-get update sudo apt-get -y install cuda # 清理 deb 安装包 rm *.deb # 安装 cuda 之后,需要重启生效 sudo reboot
验证 cuda 是否安装成功:
Shell $ nvidia-smi +—————————————————————————————+ | NVIDIA-SMI 530.30.02 Driver Version: 530.30.02 CUDA Version: 12.1 | |—————————————–+———————-+———————-+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 Tesla T4 On | 00000000:00:06.0 Off | 0 | | N/A 38C P0 26W / 70W| 2279MiB / 15360MiB | 0% Default | | | | N/A | +—————————————–+———————-+———————-+ +—————————————————————————————+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 103851 C python3 2274MiB | +—————————————————————————————+
写在前面的一点建议
建议你在使用 ssh 登录云主机时,使用 screen 命令进入一个虚拟终端会话,这可以避免因为网络不稳定而中断了正在执行的命令。因为接下来的一些命令需要下载大文件而耗时比较长。
screen 命令速记:
Bash # 新建一个 screen 会话,我的会话取名为 workspace screen -R workspace # 退出 screen 会话 ## 先按组合键 Ctrl+A ## 然后按字母 D # 当需要重新进入 screen 会话 screen -r -d workspace
详细的命令使用说明,参考 How To Use Linux Screen 。
部署 Web UI
你可以直接 clone 项目 AUTOMATIC1111/stable-diffusion-webui (又称 A1111 ) 的最新代码,然后按照 README 中的说明安装即可。
而我参考了另一个项目:
如果你想快速开始体验,就跟我一样脚本一把梭,免得耗费时间找各种插件/模型;
如果你很在意这些命令在干什么,我简单添加了一些注释;
看不懂?没关系,这个系列以后会有文章深入这些细节。
Bash #!/usr/bin/env bash # A1111 项目没有打 tag 的习惯,你拉取到的最新版本代码可能无法复现本文的内容, # 而这个项目 Fork 自 A1111 ,还贴心地打上了 tag ,建议你和我一样使用这份源码 git clone -b v2.2 https://github.com/camenduru/stable-diffusion-webui # 指定之后操作的根目录 base_dir=”$(pwd)/stable-diffusion-webui” # 简化 ariac2 下载命令 download=”aria2c –console-log-level=error -c -x 16 -s 16 -k 1M” # Extra network / Textual Inversion # 负面词,功能说明 https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Negative-prompt git clone https://huggingface.co/embed/negative ${base_dir}/embeddings/negative # Extra network / Lora # 支持把 Lora 模型作为关键词 git clone https://huggingface.co/embed/lora ${base_dir}/models/Lora/positive # 4x-UltraSharp ,一个通用模型,可以提高图片的分辨率。 # 原始模型发布在 MEGA 网盘,为了下载方便使用 huggingface 上的备份。 ${download} https://huggingface.co/embed/upscale/resolve/main/4x-UltraSharp.pth -d ${base_dir}/models/ESRGAN -o 4x-UltraSharp.pth # 一些方便的插件,可以去他们的 Github 主页查看功能介绍 ## 方便从 Web 端下载 civitai 市场的模型 git clone -b v2.0 https://github.com/camenduru/sd-civitai-browser ${base_dir}/extensions/sd-civitai-browser ## 方便从 Web 端下载 huggingface 市场的模型 git clone https://github.com/camenduru/stable-diffusion-webui-huggingface ${base_dir}/extensions/stable-diffusion-webui-huggingface ## 一个图片浏览器,方便浏览保存过的图片 git clone https://github.com/AlUlkesh/stable-diffusion-webui-images-browser ${base_dir}/extensions/stable-diffusion-webui-images-browser # 主模型 models=”${base_dir}/models” ## Stable Diffuison v1.5,SD1.5 的模型 (可选) ${download} https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors -d ${models}/Stable-diffusion -o v1-5-pruned-emaonly.safetensors ## 国风3 https://huggingface.co/xiaolxl/GuoFeng3 ${download} https://huggingface.co/xiaolxl/GuoFeng3/resolve/main/GuoFeng3.2.safetensors -d ${models}/Stable-diffusion -o GuoFeng3.2.safetensors # LoRA 模型 mkdir -p ${models}/Lora ## 墨心 MoXin https://civitai.com/models/12597/moxin ${download} https://civitai.com/api/download/models/14856 -d ${models}/Lora -o MoXin_v10.safetensors
最后我们启动 Web UI
直接通过 launch.py 启动,而不是 webui.sh ,这样可以加载额外安装的插件。
一些 Python 依赖包会在初次运行时安装。
Bash cd stable-diffusion-webui ## 初始化并启用新的 python venv 环境 python3 -m venv .venv source .venv/bin/activate ## 安装支持 cuda 11.8 的 pytorch, xformer pip install torch torchvision torchaudio torchtext torchdata –extra-index-url https://download.pytorch.org/whl/cu118 -U pip install xformers==0.0.18 triton==2.0.0 -U ## 在 10000 端口上启动 Web 服务 python3 launch.py –listen –xformers –enable-insecure-extension-access –gradio-queue –port 10000
浏览器打开 http://${host_ip}:10000 就可以看到 Stable Diffusion Web 页面了。
把 ${host_ip} 换成你的云主机 ip 地址。
P.S 安装脚本中省略了部分本文用不到的插件,所以 Web 截图会略有不同。
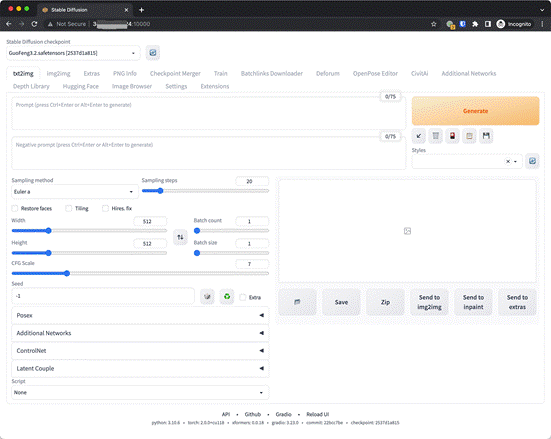
使用自建的 AI 作图环境
选择一个基础模型(主模型)
在 Stable Diffusion checkpoint\ 下拉菜单中,选择 GuoFeng3.2.safetensors 。
GuoFeng3
这是一个中国华丽古风风格模型,也可以说是一个古风游戏角色模型,具有2.5D的质感。
来自: https://huggingface.co/xiaolxl/GuoFeng3

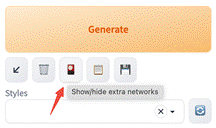
点击 Generate\ 下面的 Show/hide extra networks 图标,可以看到已经安装的模型。
切换选项卡,可以看到我们已经安装的所有 LoRA 模型。
*Q*: 什么是 LoRA 模型?
*A: 根据特定概念更改现有 Stable Diffusion 模型结果的文件。这可以是一种艺术风格、一个角色、一个现实中的人、一个物体或一个主题。一些著名的例子:Arcane Style LoRA(奥术风格 LoRA) ,Makima from Chainsaw Man LoRA(来自动漫《电锯人》中的玛奇玛)。(来自:*https://aituts.com/stable-diffusion-lora/ )
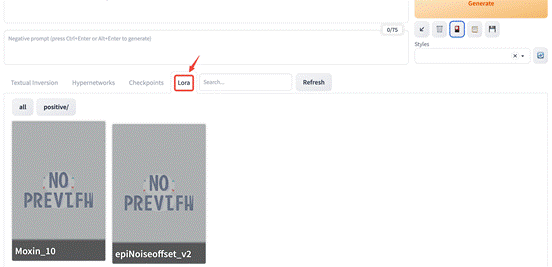
点击一个 LoRA 模型,可以看到在 Prompts 输入框中,自动填写上了模型名称:
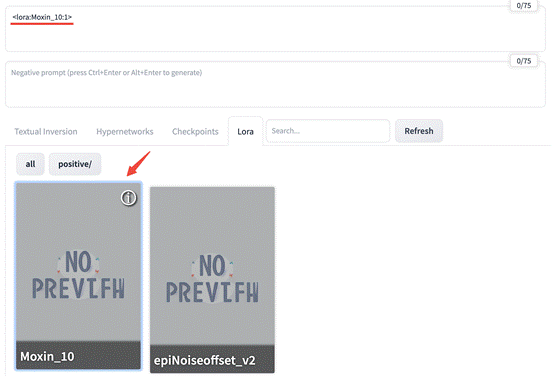
我选择 Moxin_10 这个模型。
墨心 MoXin 1.0
昔涓子《琴心》,王孙《巧心》,心哉美矣,故用之焉。
来自: https://civitai.com/models/12597/moxin
*(非常适合与国风*3 搭配使用的 LoRA 模型,可以生成水墨画风格的图片。)
从最简单的开始
准备创作,首先要有个想法:
假如我想画一只熊。
在关键词 (Prompt) 输入框中添加一句描述:
a bear
提示词目前只支持英语。
如果你有更复杂的描述,但是表达不出来?翻译软件一大把。
然后点击 Generate 进行生成,大概花了 10s,图片就生成好了。
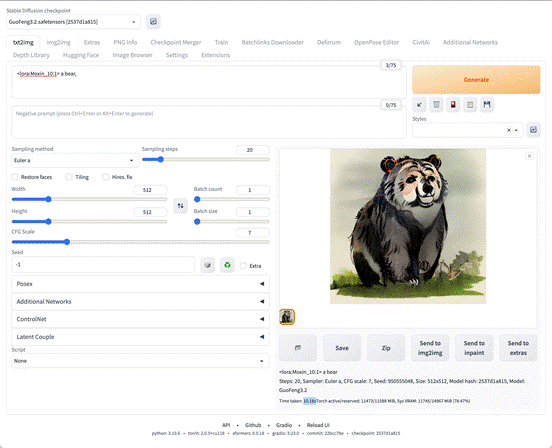
说实话,这虎头虎脑的黑熊,效果还挺萌!顿时对我们的 AI 绘画之旅,充满信心了有木有?
如果要再次生成,就继续点击 Generate ;如果要一次生成多张图片,可以调整 Batch count 。
显卡有多还可以调整 Batch size 进行并发生成😊。
点击 Generate 进行批量生成,大概花了 13s,多张图片就生成好了。
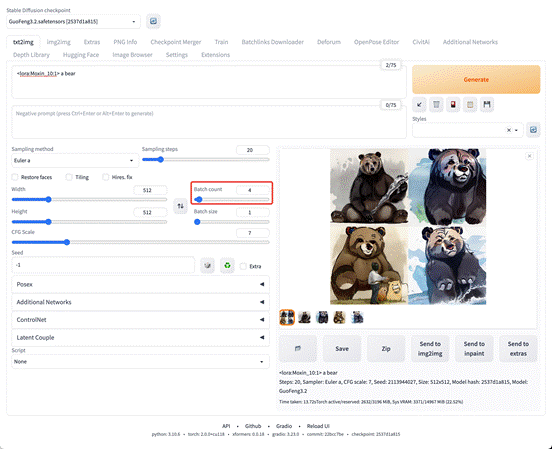
多生成几张之后会发现,奇奇怪怪的图片真不少,质量参差不齐。
获得更好的效果
首先我们可以点开模型的介绍页面,看看模型的作者都有什么建议。
根据作者的建议,我做了如下调整:
加上负面词(Negative prompt):
lowres, worstquality, low quality, normal quality, text, error, extra digit, jpegartifacts, signature, watermark, username, blurry
这些负面词,稍微翻译下,就能懂他们的意思。
修改了参数:
• Sampler: DPM++ SDE Karras
• Sampling steps: 35
• CFG Scale: 5
这里先不介绍这些参数的含义,仅仅是按照模型作者推荐的来设置。
再来点击 Generate ,生成看看。
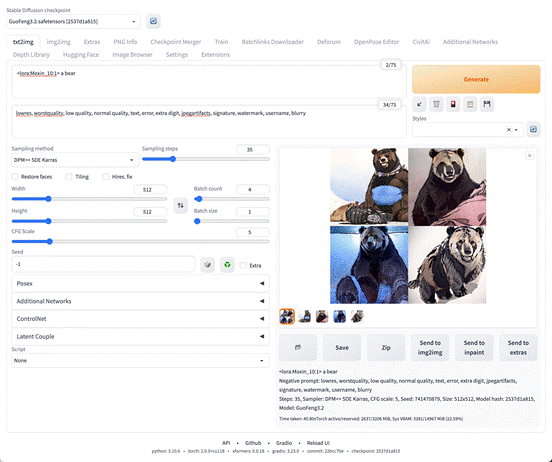
生成时间长了一些,大概 40s 。
而且通过负面词筛掉了许多质量不佳的图片素材,出图效果确实变好了许多。
赋予图片主题
我们提供的关键词过于简单,所以生成的图片没有一个统一的主题,所以我们需要细化一下需求,扩充一下提示词中的画面描述。
比如,现在我想要画一只黑熊站在枫叶林中练习挥剑。
修改关键词,把图片描述的更细致:
A black bear stood in the maple leaf forest and practiced waving his sword.
为了快速看到构图效果,可以调低 Batch count 。
再次尝试生成:
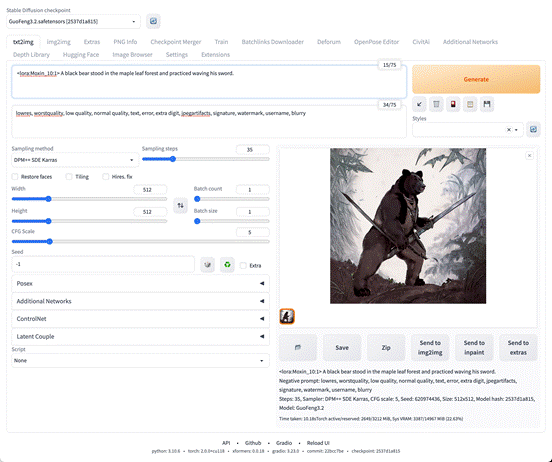
图片里的这只黑熊有“剑客”内味儿了,只是手指看起来怪怪的。
手指的的生成问题,在使用 Stable Diffusion 时很常见,我们可以暂时通过负面词去绕过这个问题。
Tips: 你如果使用和我一样的参数和关键词,填入同样的 Seed 就能复现我这张图哦~
图片生成信息中可见 Seed: 620974436 。
举一反三
当有一张图片让我们感觉不错,希望再得到类似的创意怎么做?
接下来我们以这张”灰熊剑客”的构图为基准,来生成其他的图片。
点击生成图片下方的 Send to img2img 按钮。
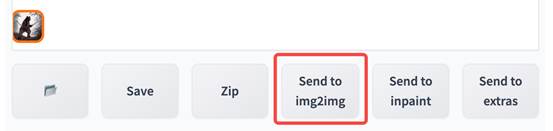
点击后会自动跳转到 img2img 标签页。仔细观察可以发现,相比之前的页面又多了 2 个可调整的参数:
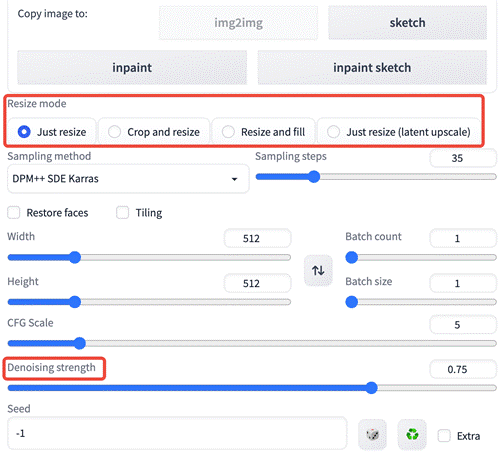
Denoising strength,去噪强度,控制与原始图像相比,它将产生多少变化:
• 设置成 0 时,不会有任何变化;
• 设置成 1 时,会得到一个无关的绘图。
那我们保持之前的参数都不变,仅仅调整 Denoising strength ,来看生成多张图片的效果。
• Denoising strength: 0.75
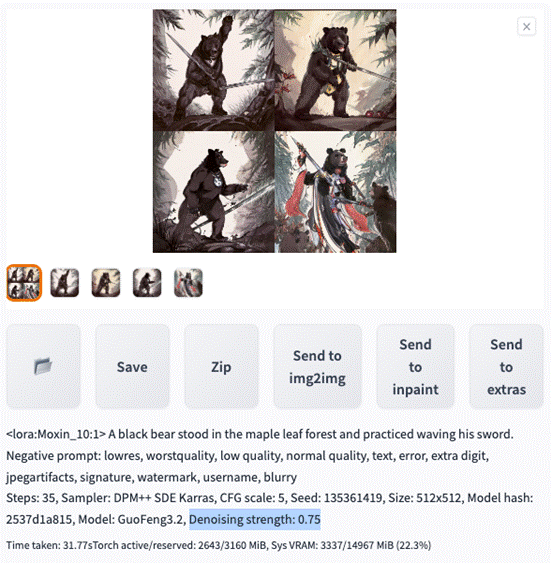
• Denoising strength: 0.35
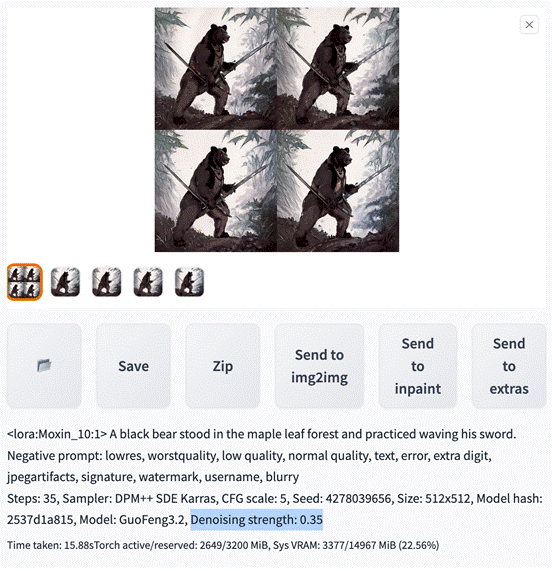
因此如果我们想要生成与原图片类似的构图,Denoising strength 取值在 0.5 以下更佳。
Resize mode,如果目标图像的宽高比与输入图像的宽高比不同,有如下几种方法可以调和差异:
• Just resize: 简单地将源图像调整为目标分辨率,可能导致不正确的宽高比。
• Crop and resize: 调整源图像的大小,保留宽高比,使其占据整个目标分辨率,并裁剪突出的部分。
• Resize and fill: 调整源图像的大小,保持宽高比,使其完全适合目标分辨率,并从源图像中按行/列填充空白。
• Just resize (latent upscale):类似于 “Just resize”,但缩放是在潜在空间中完成的。使用大于 0.5 的 Denoising strength 来避免图像模糊。
我们固定 Denoising strength 为 0 (即不生成新的绘图),尝试将 512×512 分辨率的原图调整为 300×600 的图片,观察在不同 Resize mode 下的变化。
Just resize  |
Crop and resize  |
|---|---|
Crop and resize  |
Just resize (latent upscale)  |
起初我不是很能理解 Just resize (latent upscale) 的意义 ,感觉就是让原图变得更抽象了。
当我根据说明中的提示把 Denoising strength 设置为 0.6 (即大于 0.5),再次生成:
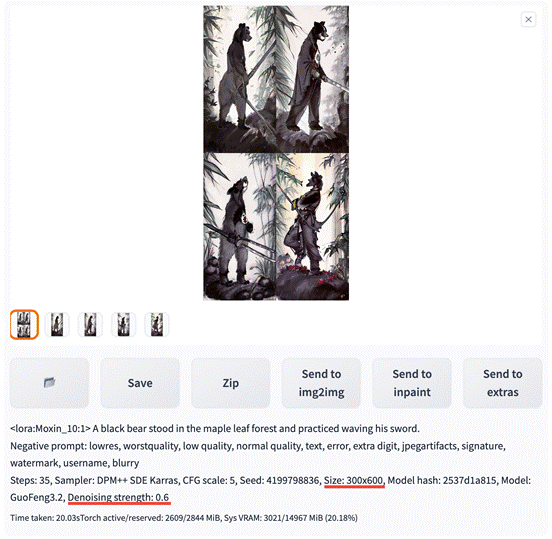
这样生成的图片是清晰的,AI 发挥了创意的同时让这一组图片中的灰熊,变得更瘦了。看来 Just resize (latent upscale) 模式主要是用来和 Denoising strength 配合的。
提高分辨率
在不那么充裕的算力资源下,为了更多更快地生成图像,我们不会设定过高的图片分辨率,但是当生成的结果让我们满意时,分辨率不达预期怎么办?
在 Stable Diffusion 中提供了 Image AI upscaler (图像 AI 升频器),比如: ESRGAN 。
找到中意的图片,点击下方的 Send to extras 按钮。
点击后会自动跳转到 Extras 标签页。但是这里的选项比较多,篇幅有限,简单给各位看官演示一下,以后文章中细聊。
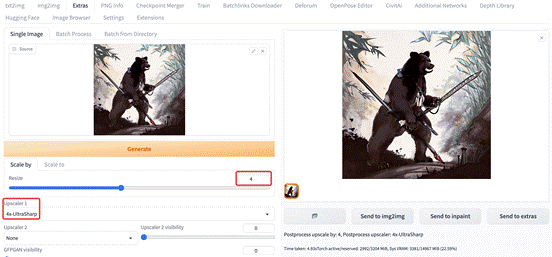
原图  |
Postprocess upscale by: 4, Postprocess upscaler: 4x-UltraSharp  |
|---|---|
继续探索
使用文本生成图片依赖合适的模型,发挥创意组合关键词(Prompts),辅以调整参数获得满意的效果。
学习资源很多,可以多看看其他人的作品。
比如: https://prompthero.com/prompt-builder/62cc0211b76
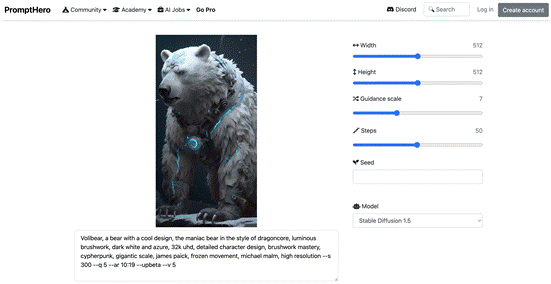
一幅作品用到的模型,做图参数,关键词都会分享出来。虽然仅凭这些不一定能复刻一个同样的作品,但是就算是照抄关键词也能发现不少有趣的东西。
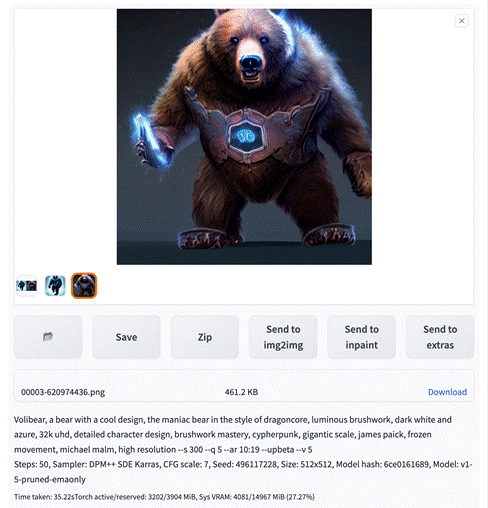
下面是我使用 Stable Diffusion 1.5 基础模型和相同的关键词生成的作品:
推荐一些发布 AI 艺术作品网站:
推荐一些 Prompts 学习笔记:
• https://www.creativindie.com/best-midjourney-prompts-an-epic-list-of-crazy-text-to-image-ideas/
• https://stable-diffusion-art.com/prompts/
推荐一些模型市场:
• https://huggingface.co/models
总结
本次给大家分享了如何开启你的 AI 绘图之旅,而 AI 艺术却不仅限于图像,如果大家对 AI 艺术感兴趣的话,推荐大家去看看这篇文章,它相当于是一个资源导航。
利用 AI 去发挥更多的创意吧!
拓展思考
*Q*: AI 能作图,那么 AI 可以帮忙写作图关键词吗?
*A*: 当然可以!但是下回再说。敬请期待之后的分享!
参考
• https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features/
• https://github.com/camenduru/stable-diffusion-webui-colab
• https://huggingface.co/xiaolxl/GuoFeng3
• https://civitai.com/models/12597/moxin
• https://developer.nvidia.com/cuda-11-8-0-download-archive
• https://pytorch.org/get-started/locally/
• https://stable-diffusion-art.com/inpainting_basics/
• https://stable-diffusion-art.com/ai-upscaler/
• https://pharmapsychotic.com/tools.html
声明:本站为个人非盈利博客,资源均网络收集且免费分享无限制,无需登录。资源仅供测试学习,请于24小时内删除,任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集。请支持正版!如若侵犯了您的合法权益,可联系我们处理。
